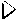McIDAS Programmer's Manual
Version 2003
[Search Manual] [Table of Contents] [Go to Previous] [Go to Next]
McIDAS-X grids are typically composed of atmospheric and oceanographic data, which are produced by numerical models or derived from observational data using an objective analysis scheme. Grids may contain any data that can be represented in a two-dimensional matrix.
Because grid data and image data can both be represented in two-dimensional matrices, it's important to know how they're different. The attributes that distinguish them are listed in the table below.
| Attribute | Grid data | Image data |
|---|---|---|

Grid data has five unique attributes: valid time, level, parameter, origin and navigation. Each is described below.
Grid data is often used to store output from numerical models that simulate the atmosphere and ocean. Because these models predict what the atmosphere or ocean will look like at some time in the future, grids must contain two different time attributes when representing model forecasts:
For example, if a model run on 17 January at 00 UTC generates forecast fields valid 36 hours later, the primary time attribute is 17 January at 00 UTC and the secondary time attribute is 18 January at 12 UTC. If the grid does not represent a model forecast, no secondary time attribute is needed.
Grids store information that represents data at some vertical location in the atmosphere. The level can be the constant height above the surface, such as 100 meters or 32000 feet; the constant pressure surface, such as 500 millibars; or some other meteorological surface, such as the level of the tropopause or isentropic surface.
The grid parameter is the data type the grid represents. Parameters can be any field that can be stored as a number, such as temperature, wind speed or dew point. Grids must also contain the stored units used in the grid.
A grid's origin refers to the process that created the grid. For example, if a grid is created by a forecast model, the origin is the name of the model, such as ECMWF or GFS. If the grid is created from another objective analysis process, that name can appear as the origin.
Navigation is the process of determining the latitude and longitude location of data points on a grid. This information is needed when colocating data points from a grid with another data type. For example, you can use this information to contour the gridded field on a satellite image displayed on the McIDAS-X Image Window.
McIDAS-X currently recognizes these grid projection formats:
The diagrams below show how a three-dimensional Earth is represented on a two-dimensional surface for the pseudo-Mercator, polar stereographic and Lambert conformal projection formats, and the orientation of the data points on these projections. A sixth grid projection format is also available, but since it has no navigation, the data points can't be converted to planetary coordinates.
For more information about grid projections and McIDAS-X navigation, see the section titled McIDAS navigation later in this chapter. |
Figure 5-3. Pseudo-Mercator projection.
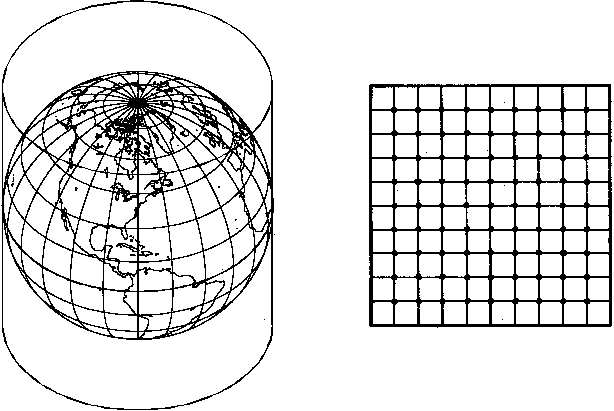
Figue
5-4. Polar stereographic projection.
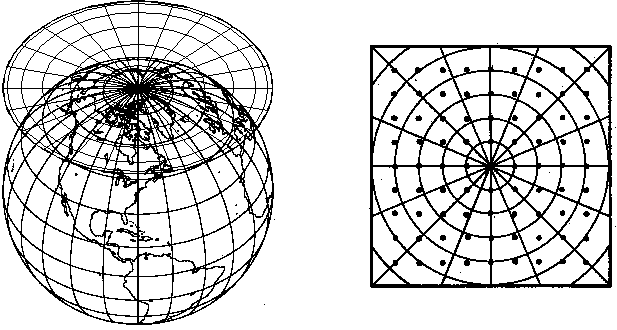
Figure
5-5. Lambert conformal secant cone (left)
and tangent cone (right) projections
Gridded data is two-dimensional data representing an atmospheric or oceanic parameter along an evenly spaced matrix. For the matrix to be useful, ancillary information about the grid must also be known. This ancillary information, along with the gridded data, is collectively called a grid object. Grid objects in McIDAS-X contain two blocks of information.
The API functions and procedures for reading and writing grid objects are described below.
Most applications for reading grid objects will do one of the following:
The table below lists alphabetically the McIDAS-X library functions for performing these tasks.
These functions are described below along with sample code, following an explanation of the selection conditions for requesting grid objects.
Applications use selection clauses to restrict the information sent from the server to the client. For example, selection clauses can restrict the search based on grid time attributes, the parameter type and level, or the process that generated the grid. Below is a list of the valid grid selection clauses as sent to the server. Additional information for each follows.
| Selection clause | Description |
|---|---|
DAY -- Use this clause to identify a list of primary days that the grids represent. For model forecast grids, these values will be the day the model was initialized. Otherwise, DAY is the Julian day the data represents.
DRANGE -- Use this clause to identify a range of primary days that the grid represents. Enter the beginning and ending day numbers and the increment between days in the range. The increment default is one day.
FDAY -- Use this clause to identify the secondary day attribute for requested forecast grids. For example, if you want only the forecast fields valid for day 1997017, specify FDAY=1997017.
FHOUR -- Use this clause to identify a list of secondary forecast hours that the grids represent. For example if you want only the 12-, 24- and 48-hour forecasts from a model run, specify FHOUR=12 24 48.
FRANGE -- Use this clause to identify a range of forecast hours that the grids represent. Enter the beginning and ending forecast hours and the increment between hours in the range. The increment default is one hour.
FTIME -- Use this clause to identify the secondary time attribute for the grids requested. Use this field with the FDAY clause to isolate grids that are valid at a particular time. The format for the arguments is hhmmss. For example, to request all grids valid at 12 UTC on day 96017, specify FDAY=96017 FTIME=120000.
GRIB -- Use this clause to select grids with the GRIB values specified for the geographic region, the parameter, the model, or the level. This is a useful way to find grids when other sort conditions provide insufficient information to differentiate between grids.
GRID -- Use this clause to access grids based on their position in specific grid files. Since this is an artifact of previous McIDAS-X API functions, avoid using this clause if a practical alternative exists.
LEV -- Use this clause to identify a list (not a range) of levels in the atmosphere or ocean that this data represents. This field is typically filled with height in millibars or words such as SFC, MSL or TRO. To retrieve data for several levels, enumerate them individually.
NUM -- Use this clause to specify the maximum number of grids returned from the server. The default is one grid. To receive all grids matching the selection conditions, use NUM=ALL.
OUT -- Use this clause to receive only the grid header. To get the entire grid header, specify ALL (default). To get only the grid file header, use FILE.
PARM -- Use this clause to specify a list of parameter types to retrieve from the server. To retrieve temperature and height fields, enter PARM=T Z.
POS -- Use this clause to specify a grid file in a dataset. This is a relative position based on the dataset description. For example, to request grid file 5010 from a dataset that contains grid files 5001 to 5100, specify POS 10.
PRO -- Use this clause to specify a projection type for a grid. The valid entries are LAMB, CONF and MERC.
SRC -- Use this clause to specify a list of grid source names to retrieve from the server. This is usually the name of the model or process that generated the grid, such as ETA, NGM or MDX.
TIME -- Use this clause to identify a list of primary times that the grids represent. For model forecast grids, these values will be the time of day that the model was initialized. The format for the arguments is hhmmss.
TRANGE -- Use this clause to identify a range of primary times that the grid represents. Enter the beginning and ending times and the increment between times in the range. The increment default is one hour. The format for the arguments is hhmmss.
You can use the m0gsort function with any application-level program to retrieve command line keyword parameters and translate them into equivalent selection clauses. The table below lists the keywords for accessing grid objects and their equivalent selection clauses. You can also set a flag in m0gsort to disable a request to contain multiple grid selection matches.
| Command line keyword | Equivalent selection clause | m0gsort restrictions |
|---|---|---|
use LAST to get the last grid in the dataset and position; when specified, all other selection conditions are ignored |
||
In ADDE, a client may request only grid headers from a server. This allows the client to sample information on a server without transferring large amounts of grid data that may not be necessary for an application. For example, the McIDAS-X GRDLIST command reads only grid headers. The ADDE interface to the grid directory is through mcgdir, which opens a connection based on a set of selection clauses for a given dataset name.
Once mcgdir opens the connection, the application makes repeated calls to mcgfdrd and mcgdrd until all grid and grid file headers are retrieved. The mcgfdrd function is called first to retrieve the grid file header, then mcgdrd is called until it can't find any more grids in the grid file. Then mcgfdrd is called again and the loop continues, as shown below.
The grid header contains a
list of ancillary information about the grid. The entries in the grid header
are described in the table below.
| Header Word | Description |
|---|---|
total size; rows * columns (not to exceed the value of MAXGRIDPT in gridparm.inc) |
|
value
of the vertical level |
|
gridded
variable type: |
|
used if the grid parameter is a time difference or time average, hhmmss |
|
used if the grid parameter is a level difference or level average; values are the same as Word 9 |
|
grid origin; identifies the type of program that generated the grid data |
|
grid
projection type: |
|
varies, depending on the grid type; see the GRIDnnnn data file in Chapter 6 for more information |
|
reserved; filled only if the grid was created by the McIDAS-XCD GRIB decoder |
|
In ADDE, a client can request an entire grid object, including the grid header and data block from the server. For example, the McIDAS-X GRDDISP and GRDCOPY commands request entire grid objects.
The mcgget function opens a connection to read the data block of a grid object. It passes an application's selection conditions for requesting grid objects from the client to the server. The return status from mcgget indicates if the application's request can be fulfilled.
The mcgget function also allows the application to separately specify the units and format of the data returned. These are not part of the selection conditions because they are required. Units may be any unit identifier valid for the data type being retrieved. The format parameter can be either I4 for integer or R4 for real number.
If a grid in the dataset satisfies the client request, a connection is established between the server and the client and the transaction proceeds. The requested grid objects are read with either the mcgridf or mcgridc function; mcgridf reads the column-major (Fortran) format, while mcgridc reads the row-major (C) format.
Unlike image objects, which require multiple calls to mcalin to get an entire object, mcgridf and mcgridc return an entire grid object with each call. Below is a sample code fragment demonstrating a mcgget/mcgridf calling pair. Note that the mcgget call must occur before mcgridf.
Writing a grid object to a grid dataset has two restrictions:
Use the API functions below to write grid objects to a dataset.
| Function | Description |
|---|---|
writes a grid object stored in column-major format to a file |
|
The request to open a connection for writing a grid object is performed by the function mcgput, which requires the following:
When writing a grid object, the application may create and initialize a file in the destination dataset using the selection conditions below.
Once the connection is open, the server expects to transfer the number of bytes specified by the entries in the grid header. Transferring too few or too many bytes will result in a error. The mcgoutf and mcgoutc functions send the grid objects to the server. mcgoutf assumes the data block is stored in column-major order; mcgoutc assumes the data block is stored in row-major order. You must call mcgput before calling mcgoutf or mcgoutc, as shown in the sample code fragment below.
In the sample code above, you will notice that the last parameter in the mcgput function is the total number of bytes to transfer from the client to the server. You must provide this number using the equation below.
total bytes = 8 + 4 * ((number of grids * 64) + (number of data points) + (number of grids))
For example, to transfer two grids to a server where the first grid has 200 data points and the second grid has 300 data points, the total number of bytes to transfer is 2528, as shown below.
[Search Manual] [Table of Contents] [Go to Previous] [Go to Next]