McIDAS User's Guide
Version 2017.2
[Search Manual] [Table of Contents] [Go to Previous] [Go to Next]
In the non-ADDE core commands (for example, IGU and MDU), all image, grid and point files are referenced by file numbers. If you don't know the file numbers, finding data can be difficult. The ADDE commands use dataset names (in a group/descriptor format) that map to datasets. If the descriptors and group names follow a logical convention, it's easy to locate the data.
The naming scheme for datasets consists of three parts:
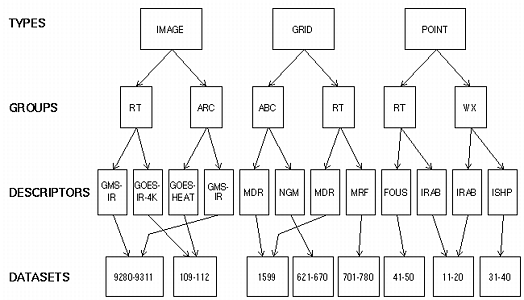
In the diagram below, type is the top tier in ADDE's hierarchical naming scheme. Image, grid and point indicate the type of data in the dataset files. McIDAS area files are image data; McIDAS grid files are grid data; McIDAS MD files are point data.
Group is the next tier in the naming scheme. A group name can be used only once under each type. The group tier in Figure 1 has three groups named RT. Notice that RT is used only once under each type.
Descriptors are the bottom tier in the naming scheme. Descriptors are not data files; they are names that point to datasets. Identical descriptors under different groups can point to the same or different datasets.
Since each ADDE command that accesses data works only with a single type, you don't have to specify the type in the command entry. For example, the command IMGDISP does not have a parameter or keyword for type because it limits its search to datasets of type IMAGE. The following command displays the most recent image in the dataset named SSEC-RT/GOES-IR-4K on frame 1, centered on St. Louis, Missouri.
[Search Manual] [Table of Contents] [Go to Previous] [Go to Next]